今日は「“ブキミの谷”、計算論的神経科学から見た決断と意志決定」ということで、今現在、私がこの問題の中で興味を持っていることをお伝えしようと思います。
極論すると、私たちの決断や選択はすべて、自分自身の遺伝子を少しでも多く残すという大きな目標の下に、そこから導かれるサブコールに従っていると考えられます。つまり食欲も性欲も金銭欲も、そこから出てくると解釈できます。そういう報酬を追い求めることでどれだけ知的なことができるかは、計算論的神経科学の世界では強化学習というテーマで研究されています。これは「起きあがりロボット」(*1)の実験です。ロボットには「頭が高いと報酬があり、転ぶと罰がある」という情報しか与えていませんが、何百回か学習すると起きあがれるようになります。
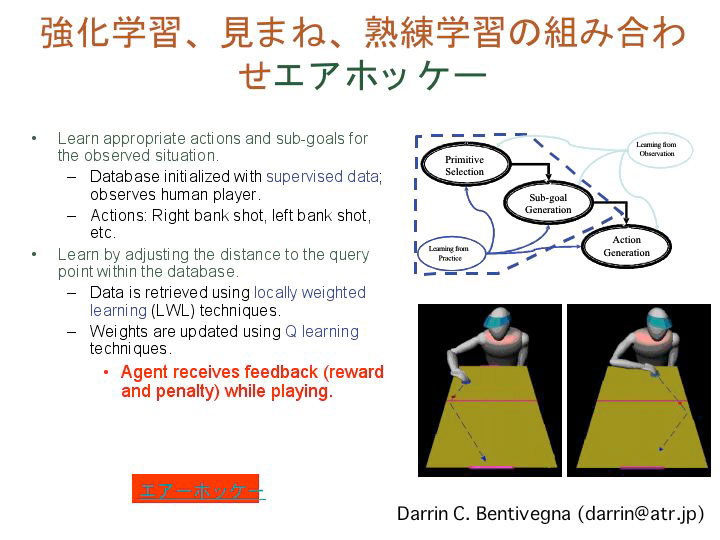
もう一つ、私たちのヒューマノイドロボットDBによる、見まねと熟練学習と強化学習についての総合的な実験をお見せします。エアホッケーの学習(*2)です。DBは2人の人間が対戦する様子を観察することで、パックがどこにある時に何をしたらいいのかを学習します。でもその段階では人間には適いません。次に強化学習を採り入れて、パックが相手のゴールに入ると報酬が与えられ、自分のゴールに入れられると罰を受けるという情報を与え、ゲームを繰り返します。そうするとDBは次第に上達し、テレビの生中継をしながら対戦する女子アナぐらいには簡単に勝てるようになります。これは報酬と罰だけの情報から、ロボットがどれだけ学習できるかという例です。
では、報酬と罰が与えられる環境の下で、人間が適切な行動を学習・決断する時には、脳のどの部分が働いているのでしょうか。学習を単純化した形の実験を紹介します。被験者は3種類の刺激図形を見て、その時に右か左どちらかのボタンを押すことを選択します。ある図形を見た時に左ボタンを押すと80%の確率で50円儲かり、20%の確率で50円損します。右ボタンを押すと損得が逆になります。この強化学習を観察していると、ドーパミンが重要な働きをしている大脳基底核の中の被核と呼ばれる部分が、自分の行動に対する報酬を予測していることが分かります。その予測の誤差は尾状核という部位で表されています。
でもこれで問題がすべて解決するかというとそんなことはなくて、大脳基底核にいかに適切な情報を入力し、そこから出た報酬予測をいかに比較するか、という大問題が残っているわけです。さらにノイズが加わることによって、その価値判断、どの行動を選ぶかが影響を受けることになります。
ブキミの谷と擬人化バイアス
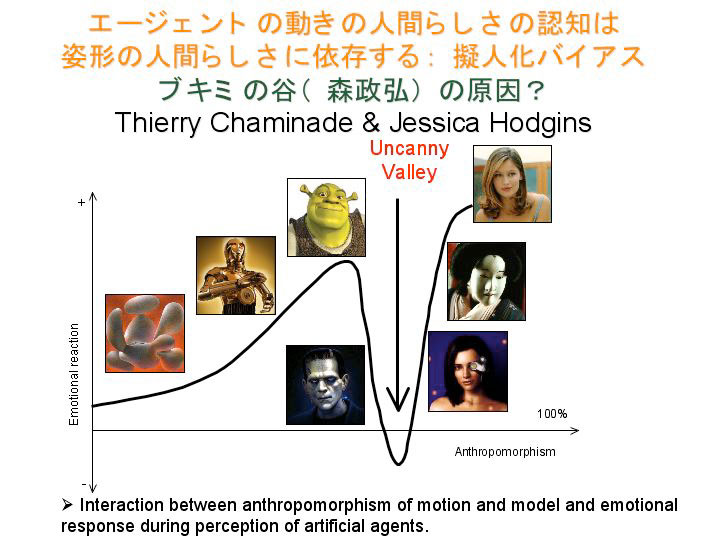
実は、人間の動きを人間らしいと感じ、人間に近いゾンビをブキミだと思うような場合にも、価値判断や情動的な反応があることが分かってきました。これは今回のテーマ“ブキミの谷”(*3)と関係します。人間の姿から遠い造形物に対しては、我々は情動的には何も感じません。それが人間に近づいてくると愛着が湧くのですが、もっと人間に近くなるとブキミに感じるようになり、そこに負の情動が生じる。そして最終的に人間にまで来るとまた好感度が増します。この負の情動を表す凹み部分が“ブキミの谷”です。
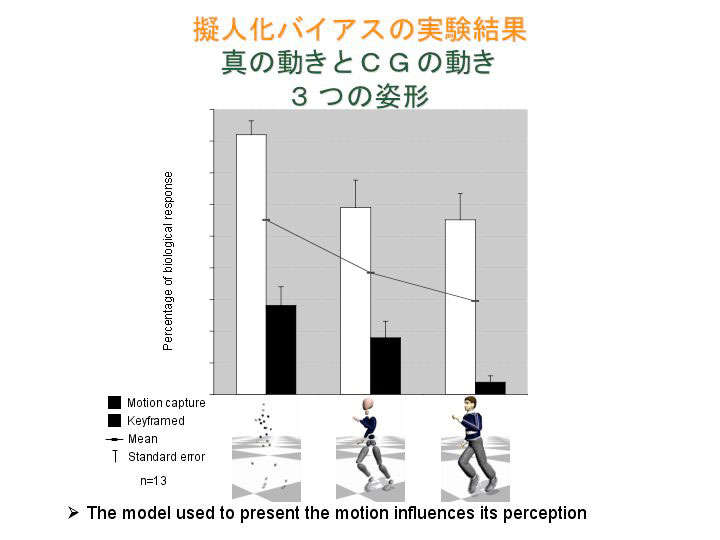
最近ではCGの世界でも、エージェントをあまり人間らしくするとヘタな動きをした時にとても不自然に感じることが分かってきています。私は“擬人化バイアス”と呼んでいますが、このことを科学的に研究するために、人間の動きとCGで作った動きを、いろいろな見かけのエージェントに貼り付けて被験者に見せ、それがどちらの動きかを判断させる実験をしました。エージェントは怪物やロボットのDB、道化師、楕円体など数種類です。その結果を解析してみると、人間の知覚は見かけに依存するということが分かりました。例えばドットモデルを使うと、人間の動きだけでなくCG合成した動きも人間らしい動きだと感じ、人間に近いフィギュアを使うと、本当の人間の動きも不自然な動きだと感じて、CG合成した動きはほとんど全員が人間の動きじゃないと判断しました。つまり、見かけの複雑さと人間への近さが擬人化バイアスに影響を与えることが分かったのです。
その原因を調べるために、fMRIであらためて実験しました(*4)。動きは人間の動きとCG合成したモノの2種類、エージェントはドットと楕円体と人間の3種類のモデルです。被験者の脳の動きを観察すると、頭の後ろの視覚野が活動するのは当然として、面白いのは、ドットモデルを見ている時は、人間のモデルを見ている時よりも前頭葉の内側部が活動するんです。一方人間モデルを見ている時は、頭の後ろに近い上側頭溝が活動します。つまりエージェントによって、刺激される部分が違うわけです。
また人間の動きを貼り付けた映像を見せている時には、運動の制御に関わると考えられている左の運動前野と小脳が活動します。ところがCG合成した動きを貼り付けた場合には、視覚の比較的高次な処理を行うとされている上側頭溝の後部が活動します。
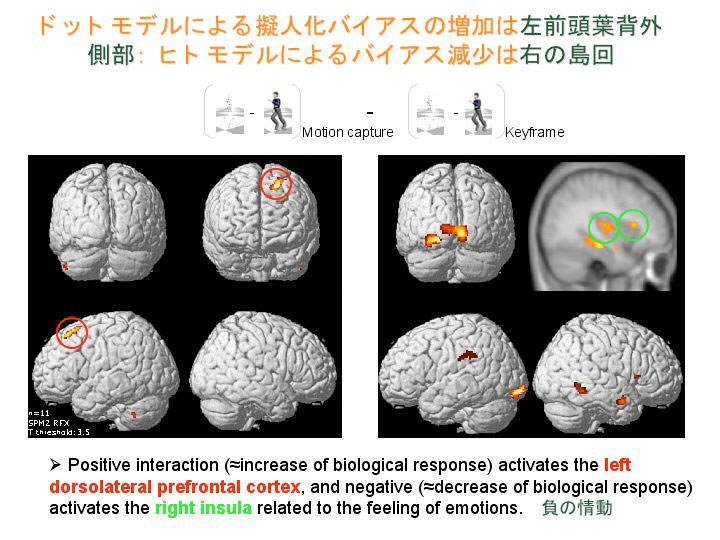
もっとも面白いのは、ドットモデルによる擬人化バイアスの増加がどこで表されているかを見ると、左前頭葉の背外側部、かなり前の部分です。一方人間のモデルの場合のバイアス減少は右の島回です(*5)。右の島回は負の情動を表すことが過去の様々な研究結果で分かっています。
これは何を意味するかというと、見かけは人間に近いけれど動きは不自然なものを見ると、右の島回が活動しブキミだと感じる。しかし単純なドットモデルであっても、その動きが人間の動きだとすると、情動とは関係しない前頭葉が判断に関わっている。つまり負の判断と正の判断は、脳の中でも全然違うところが使われるわけです。もう1つ分かったことは、人間のモデルに近い刺激を与えると視覚情報は後ろから前に向かってサッと流れるが、ドット刺激の場合はどうも情報は1回前頭葉に送られ、もう一度フィードバック経路で頭の後ろに戻ってくるらしい、ということです。
では最後に、最近話題のブレイン・マシン・インタフェース、脳とロボットのダイレクト通信についても触りだけお話したいと思います。数年前からヒトやサルの運動に電極を刺して、手の運動と関連したニューロンの活動を調べて、手の運動を予測できるようになっています。それを利用するとロボットを制御することも可能なんですね。でも私たちは、電極の代わりにfMRIでその活動を見て、汎化能力をもって当てることに成功したのです。しかも第一次視覚野と第二次視覚野の活動を見るだけで、視覚刺激として提示されたこの縞模様のうちどっちの縞に注意を向けているかも分かる。fMRIで人の心が読めるところまで至ったわけです。さらにMEGとfMRIを組み合わせることで、正確に大脳皮質の視覚野の活動をミリメートル・ミリ秒で推定できることも分かってきました。こうなると夢のような話ですが、体が動かなくなった患者さんやお年寄りがパワースーツのようなものを着けて動き回ることや、キャップを被って運動を思い描けばその通りのことをヒューマノイドロボットが再現するようなことが、将来できるようになるかもしれません(*6)。
人間と動物の違いは道具を使うことです。道具とは自分の体ではない形態の体の延長ですが、ブレイン・マシン・インタフェースができると、体の延長でさえない第2、第3の体を人類が手に入れる時代がくるわけです。そうした時、我々が決断する場合どちらの体で、どちらから得た情報に基づいて決断するのでしょう。非常にブキミだけれど面白いことが起きそうだ、ということをお伝えして終わりにしたいと思います。
|